Results
ResNet18
- Trained on the birds dataset for 5 epochs
- Learning rate was set at a constant .01
- Accuracy was not that high
- Served as a good baseline for the rest of our models
Losses:
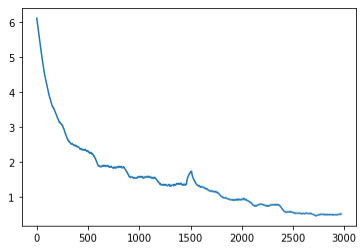
Test accuracy: 67.9%
MobileNetv2
- Trained for 10 epochs
- Scheduled learning rate to decrease by a factor of 2 from .01 starting at the 5th epoch
- Outperformed ResNet18 with accuracy of 77.6%
Losses:
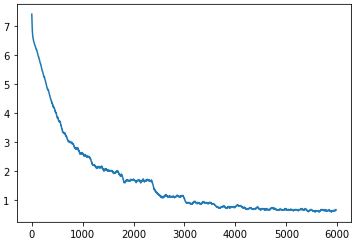
Test accuracy: 77.6%
EfficientNetb3
- Trained for 10 epochs
- Scheduled learning rate to decrease from .01 to .001 after 5 epochs,
then to .0001 after 3 more - Outperformed ResNet18 with accuracy of 74.9%
Losses:
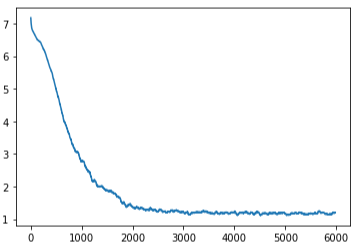
Test accuracy: 74.9%
densenet161
- Trained for 10 epochs
- Scheduled learning rate to decrease by a factor of 2 from .01 starting at the 5th epoch
- Achieved our best accuracy of 85.2%
Losses:
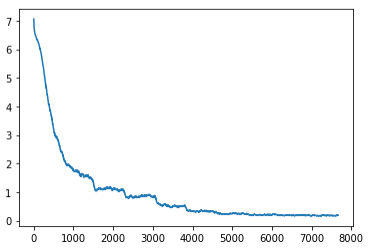
Test accuracy: 85.2% (Top 5 on leaderboards)